IN DEPTH - An in-depth analysis by HEC professors

Manage Your Talents, Manage Your Career
How to find a balance between executives and employees' objectives to attract and retain talents? How to show legitimacy and trust to align with citizens...

Make AI Your Ally
Artificial Intelligence has a potentially disruptive impact on organizations, firms, and society at large. The latest mind-boggling illustration came...


ARTICLES - Professors' analysis and research




INSTANTS - Points of view

PODCASTS




Executive Director of CDL Sonia Sennik opens Super Session proceedings ©Daniel Brown, CDL Toronto
Entrepreneurship and Startups
videos

Igor Shishlov: Do Climate Negotiations Matter?

Dominique Rouziès: Manage Your Sales Career

Hélène Löning: Why ESG Matters
News

Alyssa Rusonik is a PhD student at the Finance department of HEC Paris. In just the second year of her PhD, she has received an award for the best article from a doctoral student at the annual conference...

In 2023, five professors have been promoted at HEC Paris. Pepa Kraft and Vedran Capkun of the Accounting and Management Control department, and Xitong Li of the Information Systems and Operations...

When it comes to teaching high-level finance to executives, Ioanid Rosu knows that being both clear and memorable is key. But this academic director of the Executive MSc in Finance program at HEC Paris...

Congratulations to Dr Yufei Shen, Information Systems & Operations Management, who successfully completed his doctoral dissertation defense at HEC Paris on November 24, 2023.

At its Autumn Seminar 2023 Inquire Europe awarded the first prize to a paper co-authored by Irina Zviadadze, associate professor of finance at HEC Paris.

11 new students embarked on the long and winding journey towards a Ph.D. in September, bringing the total number of doctoral candidates at HEC Paris to 56. Hailing from as far afield as Brazil, Singapore...

HEC Paris continues its campaign to recruit world-class research professors with the arrival of 14 new academics to its faculty ranks. This maintains its long-term objective of becoming one of the world's...

Back in 2020, Open.AI's GPT3 burst onto the scene, captivating the world with its artificial intelligence capabilities. Fast forward to today, and AI models have become an integral part of our daily lives...

Extra-financial reporting, ESG indicators, extra-financial performance, responsible leadership: these are the themes of the new Mazars and HEC Paris "Purposeful Governance" Chair, supported by the Purpose...

The 25th Vernimmen Awards saw two top HEC academics rewarded for their outstanding approaches to transmitting knowledge to the business school’s students. The annual event celebrates teaching and...

Do you keep an eye on change and societal dynamics? Are you interested in becoming a spokesperson for your generation? If so, apply to become a content curator during the 2023/2024 academic year at the...

The seventh PhD Workshop in Finance united academics from around the world around the spirit and works of Denis Gromb. The late Professor of Finance at HEC Paris initiated this Workshop in 2010, providing...
Irina Zviadadze, Associate Professor of Finance at HEC Paris and affiliate researcher at the Centre for Economic Policy Research (CEPR), is the winner of the “Best Young Researcher in Finance and...

The eighth edition of S&O Research Day saw 25 high-pedigree presentations by scholars devoted to advancing interdisciplinary explorations in fields as diverse as disability inclusion in Brazil, the...

The recent CDL Super Session held in Toronto brought together around 1,200 participants, including startups, mentors, researchers, and academics, marking the first in-person gathering in four years. The...

HEC Paris was more present than ever in the annual ChangeNOW summit, organizing four sessions devoted to women entrepreneurs, transition and stability, impactful research and business for peace. The 2023...

Barely a few months after being elected to the Royal Academy of Sciences, Letters and Fine Arts of Belgium, HEC Paris Associate Professor of Data Law & Artificial Intelligence David Restrepo Amariles...

Nexans, a global group and key player in the energy transition, HEC Paris through its Society & Organizations Institute and the HEC Foundation have jointly launched the "Orchestrating sustainable business...

Congratulations to Dr Chang-Wa Huynh, Strategy and Business Policy, who successfully defended his Doctoral Dissertation at HEC Paris on July 05, 2023. Chang-Wa has accepted a position as Assistant...

Congratulations to Dr Maxime Bonelli, Finance, who successfully defended his Doctoral Dissertation at HEC Paris on July 6th, 2023. Maxime has accepted a position as Assistant Professor at London Business...

Congratulations to Dr Hanei Son, Strategy and Business Policy, who successfully defended her Doctoral Dissertation at HEC Paris on June 13, 2023.

Phasing out fossil fuels, challenging public policy, debating the implications for vulnerable populations of the transition to renewables – and highlighting some success stories. These were just some of...

Congratulations to Dr Tianhao Yao, Finance, who successfully defended his doctoral dissertation at HEC Paris on June 6, 2023. Tianhao has accepted a position as Assistant Professor at Singapore Management...

Congratulations to Dr Alexandre Madelaine, Accounting and Management Control, who successfully defended his doctoral dissertation at HEC Paris on June 6, 2023. Alexandre has accepted a position as...

Congratulations to Dr Nauman Asghar, Strategy and Business Policy, who successfully defended his doctoral dissertation at HEC Paris on May 30, 2023. Nauman has accepted a position as Assistant Professor...

Philanthro-Lab was the appropriate setting for HEC Paris’ first-ever Purpose Day. The five-hour event was devoted to the research projects conducted by the S&O Purpose Center and Purposeful Leadership...

The National Foundation for the Teaching of Business Management, FNEGE, has rewarded Alain Bloch with its prestigious label for two of his books in the Essays Category. The Professor Emeritus in...

Congratulations to Dr Francesco Grazioli, Accounting and Management Control, who successfully defended his doctoral dissertation at HEC Paris on May 11, 2023. Francesco has accepted a position as...

“How experimental research could help real world organizations address concrete social challenges”. This was the ambitious objective set by HEC’s first-ever Inclusive Economy (IE) Day, attended by...

"Taking up the challenge of an effective, efficient and sustainable Purpose (“Raison d'Être”)" was the theme of the 2nd “Grand Forum de la Raison d'Être” organized by The Why Project on April 21 at the...

The 46th edition of the HEC Foundation Awards once again highlighted the cutting-edge excellence of the school’s research at all levels. 11 prizes in nine categories were awarded to academics and students...

One of the world’s most successful short-only hedge funders, Fahmi Quadir, was the keynote speaker at a January 26 research workshop entitled “Frauds in Capital Markets: the Role of Short Sellers”. It was...

Congratulations to Dr Claire Linares who received on Monday, March 27, 2023, the prestigious HEC Foundation Doctoral Dissertation Award 2022 for her research on consumer psychology and face perception.

Dominique Rouziès, Ph.D., Professor of Marketing at HEC Paris, has won the 2023 American Marketing Association (AMA) Sales Special Interest Group (SIG) Lifetime Achievement Award for her work in the sales...

Tina M. Lowrey, Ph.D., Professor of Marketing at HEC Paris, has been elected and is currently serving as the President of the Association for Consumer Research (ACR). ACR is the premier academic...

HEC Paris Business School and Dow Jones have released the new annual Large Buyout Performance Ranking, compiled by Professor Oliver Gottschalg of the HEC Strategy and Business Policy Department. The...

HEC Professor of Law Nicole Stolowy has been appointed to contribute to the World Justice Project’s Rule of Law Index 2023 as an international expert of justice, in order to advance the rule of law...

HEC Paris Professor of Finance Stefano Lovo has had his research paper “Herding in Equity Crowdfunding” accepted for publication in the RAND Journal of Economics, the leading journal in industrial...

Last year has been marked by two crucial international conferences to decide the future of the planet and life on it. The U.N. climate change conference, COP27, at Sharm El-Sheikh, Egypt, which closed on...

What Gets Measured: Social factors coverage in corporate ESG frameworks is a new report published by Professors Marieke Huysentruyt, Bénédicte Faivre-Tavignot, Leandro Nardi, from the S&O Inclusive...

HEC Paris is ranked the top business school in Europe by the Financial Times, and research impact is part of the ranking’s factors. Indeed, HEC Paris is one of the world’s top research schools in...

Arnaud Cudennec graduated from the HEC Paris PhD program in 2020, Strategy and Business Policy, and is today Assistant Professor at The Hong Kong Polytechnic University. He can not only proud of being a...

Congratulations to Dr Marina Traversa, Finance, who successfully defended her doctoral dissertation at HEC Paris on December 7, 2022.

Congratulations to Dr Anicet Fangwa, Strategy and Business Policy, who successfully defended his doctoral dissertation at HEC Paris on December 6, 2022. Anicet has accepted a position as Assistant...

Congratulations to Dr Jamal Sakaya, Information Systems and Operations Management, who successfully defended his doctoral dissertation at HEC Paris on December 1, 2022.

Tributes for HEC Professor Denis Gromb have flooded in from colleagues, academics and former students worldwide, following the news that the Antin I.P. Chair Professor of Finance passed away on October 30...

Congratulations to Dr Mingyi Hua, Finance, who successfully defended her doctoral dissertation at HEC Paris on October 25, 2022. Dr Hua has accepted a position as assistant professor of finance, Ivey...

This year, the Scientific Advisory Board of the Autorité des Marchés Financiers (AMF) awards its young researcher prize in economics to Noémie Pinardon-Touati (HEC PhD and Assistant Professor in the...

HEC Paris welcomed 11 new research professors to its faculty ranks for this new academic year, one of the richest pickings in years. The top-class scholars join seven of the school’s nine departments...

Professor Armin Steinbach has been awarded a Jean Monnet Chair in European Union Studies by the European Commission. Armin will hold the Chair in EU Law and Economics until 2025.

The need to tackle climate change has created massive challenges for businesses and policymakers. The Climate Days organized on the HEC campus on May 30th and 31th brought together actors from the...

HEC Professor Rodolphe Durand and Veolia CEO Antoine Frérot recently published “A Broader Vision of Business: Toward a New Narrative”, the English adaptation of their 2021 work “L’entreprise de demain”...

Congratulations Maxime! The European Finance Association (EFA) DT Co-Chairs awards the best paper presented at the 2022 EFA Doctoral Tutorial to Maxime Bonelli, HEC PhD in Finance.

Congratulations to Dr Chhavi Rastogi, Finance specialization, who successfully defended her Doctoral Dissertation at HEC Paris on August 30, 2022. Dr Rastogi has accepted a postdoc position at University...

The 2022 D-TEA (Decision: Theory, Experiments & Applications) was historic in two ways: as a tenth anniversary marking HEC’s expansion into a crucial economic field. And as a moving homage to one of the...
The European Commission has published a pool of individuals eligible for appointment as arbitrators and trade and sustainability experts in bilateral disputes under trade agreements with third countries...

Congratulations to Dr Reza Alibakhshi, Information Systems and Operations Management specialization, who successfully defended his Doctoral Dissertation at HEC Paris on July 8, 2022. Dr Alibakhshi has...

Entitled “The New EU Instruments For The Protection Of The Rule Of Law: Towards A Techno-managerial Strategy?” (MEDROI), this research project led by Arnaud Van Waeyenberge, HEC Paris Professor of...

The 14th Edition of the Medici Summer School in Management studies was held on HEC Paris campus from June 12th to 17th, 2022. Hosted this year by the S&O Institute and co-organized with the Bologna...

Congratulations to Dr Olga Ivanova, Management and Human Resources specialization, who successfully defended her Doctoral Dissertation at HEC Paris, on June 24, 2022. Dr Ivanova has accepted a postdoc...

Itzhak Gilboa, Professor of Economics and Decision Sciences at HEC Paris, has been ranked 6th theoretical economist in the world in a study by Stanford University.

Congratulations to Dr Wei Zhao, Economics and Decision Sciences specialization, who successfully defended his Doctoral Dissertation at HEC Paris, on June 21, 2022. Dr Zhao has accepted a position at...

Congratulations to Dr Noémie Pinardon-Touati, Finance specialization, who successfully defended her Doctoral Dissertation at HEC Paris, on June 20, 2022. Dr Pinardon-Touati has accepted a position at...

Congratulations to Dr Debtanu Lahiri, Strategy and Business Policy specialization, who successfully defended his Doctoral Dissertation at HEC Paris, on June 7, 2022. Dr Lahiri has accepted a position at...

Congratulations to Dr Claire Linares, Marketing specialization, who successfully defended her Doctoral Dissertation at HEC Paris, on June 3, 2022. Dr Linares has accepted a position at the University of...

Since 2015, the Society & Organizations Institute (S&O) have been coordinating informal monthly meetings to discuss some of the latest research by its 60 academics, HEC doctoral students and visiting...

One of the most keenly anticipated annual research gatherings returned to its 100% in person format on May 13, as HEC Paris hosted top academics to debate over topics as diverse as migration, business...

Congratulations to Noémie Pinardon-Touati, one of the 6 winners of the 2022 AQR (Applied Quantitative Research) Top Finance Graduate Award. This prestigious prize rewards the six best students in finance...

L’Oréal International Research Chair Yangjie Gu has been nominated by Poets&Quants as one the 2022 top MBA professors thanks to the “dynamic” and “energizing” learning environments she brings to the...

For the first time in its decade-long history, the annual EIASM Workshop on Top Management Teams (TMT) and Business Strategy Research was hosted by HEC Paris at its Jouy-en-Josas campus. Considered one of...

Daniel Halbheer, Associate Professor of Marketing and holder of the FII Institute chair on “Business Models for the Circular Economy” at HEC Paris, has his research on Carbon Footprinting and Pricing...

Jean-Édouard Colliard, Associate Professor of Finance at HEC Paris and co-holder of the Analytics for Future Banking chair (HEC Paris — Natixis — Polytechnique), is the winner of the “Best Young...

The book "En quête de sens: dialogue entre dirigeants et futurs dirigeants" (In search of meaning: dialogue between leaders and future leaders), published on March 16 by Dunod, is a choral work in which...

Assistant Professor of Strategy and Business Policy at HEC Paris, Georg Wernicke, was conferred the 2022 Best Paper Award from the German Academic Association of Business Research (VHB), for his...

The Association for Information Systems (AIS) has selected Professor Shirish C. Srivastava as a "Distinguished Member - Cum Laude", which is based on a continuous and worthy leadership contribution to the...

For the first time in its 32-year history, the Case Centre, a leading independent case-publishing platform, has rewarded not one, but two, HEC academics in the same year for their outstanding case work in...

A team of leading economists and lawyers specialising in EU affairs propose an ambitious yet feasible blueprint for reforming the European macroeconomic policy system in a CEPR Policy Insight.

Professor Alberto Alemanno has been bestowed the 2022 Schwab Foundation Social Innovation Thought Leader of the Year Award at the World Economic Forum in Davos for his decades-long investment in...

HEC Paris organized with Ecole polytechnique its first-ever symposium exploring the borderlands of law, technology and society on December 1-3, 2021. It brought together researchers and professionals from...

More than a dozen of HEC’s top faculty members paid a visit to Station F in early December as part of a learning expedition to the world’s biggest startup campus. This was designed to further solidify the...

The fourth Data Day saw a welcome return to in-person presentations and conversations. 21 months after its previous edition, this hybrid event involved 150 practitioners, researchers and students gathered...

A total of seven new professors have reinforced the ranks of HEC’s world-class academic staff. Allow us to introduce you to the seven arriving on campus: Yann Algan, Pablo M. Baquero, Julien Grand-Clément...

Thierry Foucault, HEC Chaired Foundation Professor of Finance, has been appointed co-managing editor of the Journal of Financial and Quantitative Analysis (JFQA) last September.

The Journal of Finance, one of the top journals in financial economics, just published the paper “Inventory Management, Dealers' Connections, and Prices in Over-the-Counter Markets” by HEC Paris finance...
David Restrepo Amariles, Associate Professor at HEC Paris’ Department of Law and Tax, has been asked to serve as the Chair of the Artificial Intelligence Special Interest Group (SIG) of the American...

Andreas Lanz’s dissertation-based article was selected to receive the 2021 Don Lehmann Award, established by the American Marketing Association. Andreas Lanz is Assistant Professor of Marketing at HEC...

Associate Professor of Finance Daniel Schmidt has had his research paper “Fundamental Arbitrage under the Microscope: Evidence from Detailed Hedge Fund Transaction Data” accepted for publication in the...

The case “Private Equity and Infrastructure : Antin's TowerCo Deal” written by Denis Gromb has won the prestigious AFFi*-CCMP Prize. This recognizes the year’s best case in Finance and rewards an original...

The annual Pierre Vernimmen Teaching Prize, sponsored by BNP Paribas, recognizes HEC Paris professors for their innovative pedagogy. The Pierre Vernimmen Prize is where the world of education meets the...

Bruno Biais, professor of finance at HEC Paris, was granted an Honoris Causa Doctorate by the University of Zurich, recognizing his fundamental contributions to Finance and Economics.

The latest research paper by the HEC Paris SMART Law Hub team in collaboration with Eura Nova research team was accepted by the International Conference on AI and Law (ICAIL) 2021.

Congratulations to Dr Arnaud Cudennec, Strategy and Business Policy, who successfully defended his Doctoral thesis at HEC Paris, on June 23, 2020. Arnaud will join the Hong Kong Polytechnic University (...

Thierry Foucault, professor of finance at HEC Paris and GREGHEC (CNRS/HEC), and the Scientific Co-Director of Hi! Paris Center*, is one of 209 new recipients of the European Research Council (ERC)...

Marketing strategists and consumers are only beginning to understand the impact of the subconscious on purchasing decisions. Yet, neuroscientific research indicates it is hugely disruptive to rational...

A research paper by Kristine de Valck, Marketing Professor at HEC Paris, has been nominated finalist for the Weitz-Winer-O’Dell Award of the Journal of Marketing Research. The paper, co-written by former...

HEC Paris Professor of Economics and Decision Sciences Itzhak Gilboa and fellow researchers have co-published an article calling for a dialog with decision makers. The recently-published article,...

An unprecedented 13 awards were attributed by the HEC Foundation for outstanding academic work from the school’s students and professors in 2020. The March 23 event was the 44th edition of the annual...

The Finance Department at HEC Paris is pleased to announce that Associate Professor Ioanid Rosu has had his research paper “Evolution of Shares in a Proof-of-Stake Cryptocurrency” published in Management...

The 2030 Sustainable Development Goals (SDGs) game is taught at HEC Paris. Also known as the Global Goals, the 193 member states of the United Nations agreed in 2015 to achieve them before 2030. The SDGs...

Johan Hombert, professor of finance at HEC Paris, has been selected for a European Research Council (ERC) Consolidator Grant, making HEC Paris recipient of two ERC grants in 2020, and three in total.

The Finance Department at HEC Paris is pleased to announce that Associate Professor Christophe Spaenjers has had his research paper on the profitability of real estate accepted for publication in the...

In 2020, the Society &Organizations Institute (S&O) marks 12 years of research on the notion of an inclusive global economy with the report “Inclusive Business: What it is and Why it Matters”. This third...

Congratulations to Dr Ashkan Faramarzi, Marketing specialization, who successfully defended his Doctoral dissertation at HEC Paris, on December 14, 2020. Ashkan joined the ESDES - Lyon Business School as...
The Finance Department at HEC Paris is pleased to announce that Associate Professor Irina Zviadadze has had her research paper on risk-return trade-off accepted for publication in the Review of Financial...

The 2020 Race to Zero campaign mobilized academics, business professionals and militants in a 11-day November series of virtual dialogues on climate-related issues, climaxing with the November 19 Finance...

Read why Arnaud Cudennec decided to pursue a PhD and why he decided to join the PhD program at HEC Paris

This year, five research professors join the ranks of HEC Paris’ faculty, making it a total of 116 HEC research professors in the faculty. The newcomers’ focus of research includes revenue management...

Professor Johan Hombert initiated a blog on finance to keep in touch with his students at HEC Paris by helping them understand the COVID-19 crisis, during and following the lockdown in France. The blog...

International Podcast Day celebrates its sixth birthday on September 30 and HEC Paris will join in the celebrations by officially launching its academic-based podcast "Knowledge@HEC" with one vision...

Congratulations! The AoM Career Division, Arnon Reichers 2020 Best Student Paper Award goes to HEC PhD Olga Ivanova and her co-author, HEC Professor Roxana Barbulescu, for their paper "Specializing...

This year’s winner of the Best Dissertation Award in the Technology & Innovation Management (TIM) Division at the Academy of Management Conference is Elie Sung, Assistant Professor of Strategy and...

Tomasz Obloj, Associate Professor of the Strategy and Business Policy Department at HEC Paris, has his latest paper accepted for publication in the Strategic Management Journal.

The Strategy and Business Policy Department at HEC Paris is proud to announce that Assistant Professor Ankur Chavda has been shortlisted for the 2020 Strategic Management (STR) Division Wiley Blackwell...

How to foster business dynamism when we emerge from COVID-19? New research shows that well designed unemployment insurance is key. Professor of Finance Johan Hombert (HEC Paris), with three researchers...

The HEC Paris Finance Department is proud to announce that HEC Ph.D. student Huan Tang is one of the six winners of the 2020 AQR Top Finance Graduate Award.

HEC Paris Professor Sihem Ben Mahmoud-Jouini wins the best paper award of Research-Technology Management Journal, for her 2019 published article co-authored with Didier Boulet, Chief Design Officer of...

In early 2020, the European Research Council (ERC) granted €450 million for Europe’s long-term research, because "Europe’s future depends on science and research", reminded Mariya Gabriel, European...

The 2020 HEC Data Day once again brought together a wide array of researchers, students and professionals in an expanded format designed to showcase some of the school’s salient research and applications...

The HEC Foundation Prizes were awarded on January 8 during the Matin HEC event, in the presence of Geoffroy Roux de Bézieux, President of the MEDEF. Each year, thanks to the support of its donors and...

Congratulations! HEC PhD Student, Maxime Bonelli, wins the 2019 SUERF/UniCredit Foundation Research Prize, with his paper "Labor Mobility and Capital Misallocation in the Mutual Fund Industry." Maxime...

The October 3 Faculty Day featured welcome speeches for a dozen academic figures who join the ranks of HEC research professors, now numbering a total of 120. Faculty & Research Dean Jacques Olivier and...

On Thursday June 20, 2019, we launched our new fundraising campaign for HEC Paris, “Impact Tomorrow”, with the ambitious objective of collecting €200 million over five years.

HEC’s 11th D-Tea conference saw leading academics in decision-making theory discuss ambiguity. The two-and-a-half day event in central Paris honored one of the ambiguity pioneers, David Schmeidler and...

Warm congratulations to all our 2019 PhD graduates. Ali Shantia (Information Systems and Operations Management) - Charles Boissel (Finance) - Elena Fumagalli (Marketing) - Elena Plaksenkova (Strategy and...

The 4 Nations Cup is an international competition for young finance researchers, presenting their latest research. Representing four nations, the contestants compete for the support of the audience who...

HEC Professor of Law Nicole Stolowy contributed to the World Justice Project's Rule of Law Index 2019 as an international expert, in order to advance the rule of law worldwide.

Braving the January 22 snowstorms, around 100 academics, students, company representatives and sponsors attended HEC’s second on-campus Data Day, a wide-ranging conference devoted to the impact of data on...

Congratulations Yin! Best PhD Thesis awarded to Yin Wang (HEC PhD 2018) for his " Essays on Corporate Disclosure " under the direction of Vedran Capkun, HEC Associate Professor of Accounting and...

Harvard Business Review article by Muhammad Yunus, Frédéric Dalsace, Bénédicte Faivre-Tavignot and David Menascé

For the third time in three years, an HEC Paris professor has bagged a Case Centre Award for a bestselling case study. Professor of Finance Denis Gromb won the 2018 prize in the Finance, Accounting and...

Hervé Stolowy, Professor of Accounting and Management Control at HEC Paris, received the 2017 Trophy of Accounting Excellence Award as a teacher-researcher.

On September 18, 2017, Nobel laureate Eric Maskin became the latest recipient of the HEC Paris Honoris Causa Professor Award, a title which recognizes the works of exceptional heads of states, professors...

If your name is Fred, do you look like a Fred? You might – and others might think so, too. This is the results of the highly original study by researchers including HEC Paris Professor Anne-Laure Sellier...

The pathway to reduce emissions and to limit global warming to 2°C will require substantial investment in clean energy technology. During the event: “The 2°C Challenge, Climate is our Business” – co...

The “The 2°C Challenge, Climate is our Business” event – coorganized by HEC Paris, its SnO Center and HEC Alumni – took place on October 1st 2015. It brought students, professors, alumni, and HEC partner...

Since 2008, a vibrant community of professors and PhD students has established a new inter-disciplinary center at HEC Paris: Society & Organizations (SnO). Its stated mission is to guide organizations...

For its 18th edition, the BNP Paribas and HEC Paris’ Vernimmen Teaching Prize has awarded Tomasz Obloj, Professor of Strategy and Business Policy and Michael Loy, Affiliate Professor of Law. The Vernimmen...

The Society & Organizations and Golden for Sustainability research centers recently ran a 2-day international workshop entitled “Towards a Sustainable Economy” at the HEC Paris campus. SnO and Golden were...

On May 27th-29th 2015, HEC Paris in partnership with the AXA Research Fund organized the 7th edition of its D-TEA (Decision: Theory, Experiments, and Applications) conference. The event took place in...

Professors Shirish Srivastava and Stefan Worm were awarded Syntec Prize 2015 for their research in Operations Management and Information Technology, and Marketing. For its seventh edition, the SYNTEC...

In their article ‘Reaching the rich world’s poorest consumers’ (Harvard Business Review, March 2015), Frédéric Dalsace, professor of marketing and Social Business, Entreprise and Poverty chair professor...

Dominique Rouziès, EDF Chair Professor at HEC Paris organized a conference on March 26th at HEC Paris on social selling in collaboration with Novamétrie, EDF Entreprises, Adobe, Axa and Viadeo, and the 79...

Among 187 entrepreneurial leaders; heads of state, CEOs, Olympic gold medalists and Nobel Prize winners, Alberto Alemanno, Professor of Law at HEC Paris is named "2015 Young Global Leader" by the World...
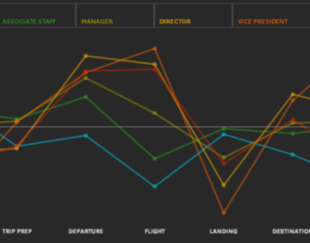
In their latest paper “Global Business Travel Builds Sales and Stress: The 7 Stages of Business Travel Stress” (featured in the HBR Blog Network of the Harvard Business Review1), HEC Paris professors...

After Philip Valta in 2013, Johan Hombert, HEC Paris Assistant Professor in Finance and member of the Research Laborotary GREGHEC has won the prize of the “Best Young Researcher” by the Fondation Banque...

Christophe Pérignon, Associate Professor in Finance at HEC Paris and Specialist in Financial Risk Management, has received the prize for the Best Young Researcher in Finance 2014, awarded by the Institut...

To answer this central question, Hi! PARIS research fellow Xitong Li invited five leading AI scholars and two representatives from French companies to take part in a full day workshop on AI and the...