


- Les modèles d’IA supposent souvent des données neutres, alors qu'en réalité, les humains manipulent stratégiquement leurs entrées.
- Même les algorithmes à enjeux élevés utilisés dans la finance ou le recrutement peuvent être biaisés par des comportements trompeurs.
- Les tests d’étalonnage et algorithmes sans regret ne sont pas toujours résistants face aux agents stratégiques.
- Notre modèle de théorie des jeux montre qu’ils peuvent réussir les tests prédictifs en déformant ou omettant des informations.
L'IA a un impact significatif sur notre vie quotidienne, rendant les interactions avec les algorithmes de plus en plus courantes. Ces algorithmes s'appuient sur des données historiques pour identifier des modèles et formuler des recommandations, par exemple en suggérant des investissements ou en filtrant des candidatures à des emplois. Cependant, les recherches en économie et en informatique n'expliquent pas ces nouvelles interactions. Nous avons créé un modèle qui analyse comment les individus peuvent interagir de manière stratégique avec les algorithmes d'IA et influencer leurs résultats afin de servir leurs propres intérêts.
Comment tromper l'IA ?
Les algorithmes d'IA, en tant que machines, partent du principe que les données qu'ils traitent sont impartiales et proviennent de sources externes. Cependant, dans de nombreux cas, les données sont fournies par des individus, qui les déforment souvent pour servir leurs propres intérêts. Par exemple, les analystes financiers biaisent leurs prévisions pour obtenir des commissions élevées, tandis que les candidats non qualifiés adaptent leur CV avec des mots-clés ciblés pour passer les filtres.
Comment devons-nous répondre de manière optimale aux algorithmes d'IA ? Ces algorithmes fonctionnent-ils bien avec les sources de données stratégiques ? Il est essentiel de comprendre ces dynamiques, car elles influencent la prise de décision dans des secteurs tels que la finance, les marchés en ligne et les soins de santé.
Mes recherches visent à explorer les interactions entre les individus "égoïstes" et les algorithmes, en mettant l'accent sur la nécessité de disposer d'algorithmes qui tiennent compte des comportements stratégiques. Cette approche peut conduire au développement d'algorithmes d'IA plus performants dans des environnements complexes et stratégiques.
Face à cette problématique, nous avons élaboré, avec Vianney Perchet, professeur au Centre de recherche en économie et statistique (CREST) de l'ENSAE, un modèle basé sur la théorie des jeux afin d'analyser l'interaction entre un agent stratégique et un algorithme d'IA.
Comment tromper l'IA avec des prévisions stratégiques
Considérons une interaction répétée entre un analyste financier et un investisseur. Chaque jour, l'analyste prévoit les chances qu'un actif soit rentable. Les analystes ont tendance à exagérer ces chances afin d'obtenir une commission sur la vente de l'actif. Par conséquent, l'investisseur ne souhaite suivre leurs recommandations que si elles sont crédibles.
Prenons l'exemple d'une plateforme d'IA qui utilise un test statistique pour vérifier la fiabilité des prévisions de l'analyste. Elle ne transmet les prévisions que si elles passent le « test d'étalonnage ». Ce test vérifie si les prévisions correspondent à ce qui se passe réellement. Par exemple, si un analyste prévoit une probabilité de profit de 60 % sur cinq jours, le test vérifie s'il y a eu un profit pendant environ trois de ces jours. L'étalonnage est essentiel pour les prévisions et sert à évaluer la précision des marchés prédictifs.
Test d'étalonnage
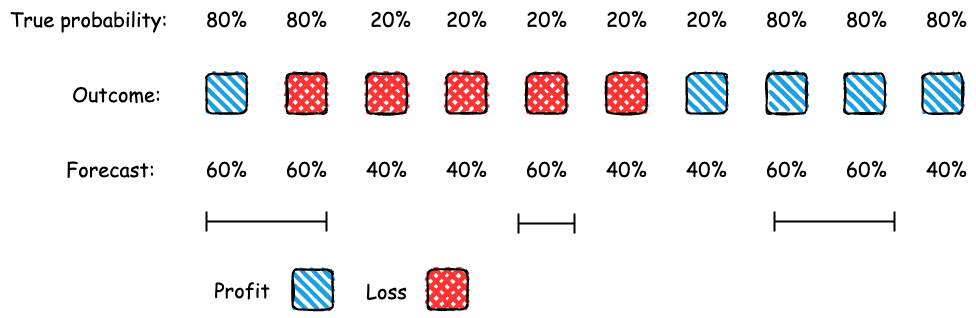
Étant donné que l'analyste doit réussir le test d'étalonnage, quelles stratégies peut-elle utiliser pour envoyer des prévisions ? Un analyste compétent peut toujours réussir le test d'étalonnage en faisant preuve d'honnêteté dans ses rapports. Supposons, par exemple, que si un actif est rentable aujourd'hui, il y a 80 % de chances qu'il le soit demain ; s'il n'est pas rentable aujourd'hui, il y a 20 % de chances qu'il le soit demain. L'analyste peut rapporter ces probabilités en toute honnêteté pour réussir le test d'étalonnage.
Y a-t-il d'autres moyens pour l'analyste de réussir le test ? Oui, elle pourrait brouiller (ou ajouter du bruit aux) prévisions véridiques. Par exemple, elle pourrait alterner entre des prévisions de 60 % et 40 % de manière aléatoire, tout en réussissant le test d'étalonnage. Si les prévisions doivent rester exactes, elles peuvent toutefois être moins précises (ou moins informatives) que les prévisions véridiques. Cela signifie qu'il est possible de faire des prévisions stratégiques, ce qui permet à l'analyste d'obtenir de meilleurs résultats qu'en se contentant d'être véridique.
Pourquoi l'apprentissage sans regret n'est pas infaillible
Nous avons également examiné ce qui se passe lorsque l'investisseur utilise des algorithmes d'apprentissage sans regret pour prendre ses décisions. Le regret mesure la différence entre ce que l'on aurait pu obtenir et ce que l'on obtient réellement. Les algorithmes sans regret garantissent qu'avec le recul, un investisseur n'aurait pas pu faire mieux en faisant systématiquement le même choix. Cependant, nous montrons que l'utilisation d'un algorithme sans regret peut conduire à une performance moins bonne pour l'investisseur que s'il s'appuyait sur le test d'étalonnage.
Nous avons constaté que les agents peuvent manipuler les données à leur propre avantage, ce qui peut nuire au bon fonctionnement de l'algorithme. Il est donc essentiel de savoir qui fournit les données et quelles sont ses motivations. Cela souligne la nécessité urgente de créer des critères de référence pour évaluer la performance des algorithmes dans les environnements stratégiques.
Pour une IA conçue de manière responsable et stratégique
Cette recherche examine comment les individus interagissent stratégiquement avec les algorithmes d'IA, en se concentrant sur la manipulation des données. En analysant son impact sur les prédictions et les recommandations, cette recherche ouvre de nouvelles voies à la croisée de l'économie et de la science informatique.
Ces conclusions s'inscrivent dans la mission du Hi! PARIS Center qui consiste à faire progresser la recherche responsable en matière d'IA et à concevoir des systèmes d'IA robustes qui favorisent la confiance et la fiabilité.
Cela est particulièrement pertinent dans des secteurs tels que la finance et la santé, où des recommandations biaisées peuvent avoir des implications sociétales importantes, telles que des disparités économiques et un accès inégal aux services.
Une traduction assistée par LLM.
Sources
Article basé sur "Calibrated Forecasting and Persuasion" de Atulya Jain (sous la supervision du professeur Tristan Tomala, HEC Paris) et Vianney Perchet (CREST, ENSAE). Cette recherche est financée par le Hi! PARIS Center.




